In my CS488 class, right after Semiramis, the final project was one where students created their own assigments, within a structure of guidelines. I chose to create a simple rendering pipeline, from modelling package to rendering. I gave this pipeline the (very original) name "photon".
To work on the car I wished to model, I required geometry mirroring, something Milkshape did not handle at the time. To remedy this, I wrote a stand-alone tool called msmirror which looked for specific tags in group names and mirrored geometry right in the .MS3D file. This tool operated on the command-line, and simply transformed the source file by adding or re-mirroring existing geometry. This way, I was able to mirror one side of the car to obtain the other.
I also required more sophisticated UV mapping and texture paging functionality than was available. I thus created a second tool to process .MS3Ds, called msmapper. This interactive tool allowed me to map and texture page each group within the model individually, changing projection types, etc., and save the results back to the model. This granted me much finer control over UVs and texture pages than was otherwise available.
With great pain, I modelled a Subary Impreza WRX STi by pushing vertices, which was great fun and a good learning experience. The resulting polygon mesh is gross, but hey you have to start somewhere.



I still had no good texture for the wheels, however, when one day I saw a beautiful STi parked outside a restaurant right beside where I lived. I walked right into the restaurant and went from table to table until I found the owner, from whom I requested permission to photograph the car and its wheels.

My tool used a a few simple heuristics to do its job. It would begin by first splitting any vertices as required to handle any texturing and normal requirements, since fixed-pipeline OpenGL doesn't support independent indexing for separate attributes. Next, it would create fans around any vertex used by 8 or more triangles:

Lastly, it would create strips by brute force, using a few heuristics. It would first examine each of the remaining unbatched triangles and locate the triangles with the lowest number of unbatched neighbours (treating any triangle pair with an edge in common as neighbours):
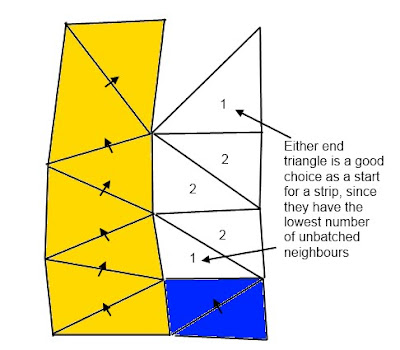
In the set of triangles with the lowest number of neighbours, it would iterate over each triangle's vertices and sum the number of triangles who used that vertex. It would the prefer triangles for which the sum was lowest:

The goal of this last heuristic was to make the algorithm try to strip "dangling triangles" on the edge of the mesh sooner, because these were more likely to become orphans later down. Without it, the algorithm frequently picked triangles in the "middle" of the mesh as starting points, which not only left a bunch of orphans on the edges but also sometimes "cut" an arbitrary stripped path from the center of the mesh to its edge, cleaving the space of available triangles for strips to be formed afterwards. I'm definitely not sure this last heuristic is advantageous in the general case, however - it may just be because of my input data. I would have needed to try my tool on more data sets to be sure.
Once the set of starting "problem triangles" was known, a simple brute-force search across all edges of the triangles in the starting set was made to find which edge and winding order yielded the longest strip. This strip was saved and the process was repeated until all triangles were batched.
The quality of the resulting strips and fans depended on the inputs:

I also included a real-time blurring test, done by rendering many lightly-transparent quads with the same texture, slightly offset from each other:

My goal with this project was to try out a simple method of minimizing graphics pipeline state changes while rendering a scene, since state changes were (and still are) quite expensive. In order to concentrate on this, I stuck to the OpenGL fixed pipeline model; the scene didn't really require anything programmable anyway, and that axis of exploration was sort of orthogonal to the state change issue.
The idea implemented by photon is simply that each logical object that requires rendering - be it a solid 3D model, a transparent 2D HUD element, whatever - registers a so-called "render key" with the rendering system. As far as the rendering system is concerned, this key is a kind of proxy for the rendered object; when rendering, all render keys in the system are traversed in a specific order outlined below, and they are all told in turn to render their payload. In this fashion the entire scene is rendered.
What's more interesting is what each render key contains, and how the rendering order is determined. When generated, a render key is made to contain a 32-bit "hash" of the rendering state required for the payload to be delivered. (More bits could be used for a more complex set of states.) For example, it might indicate that it requires a perspective projection, with client states enabled, texturing enabled, no texture coordinate generation, normal normalization on, lighting off, fog off, depth testing enabled, no culling, standard blending, all in the 2nd global rendering pass with a given texture ID, etc. This information is combined into the 32-bit key in such a way as to encode information relating to more expensive state changes in the high-level bits of the hash, and information pertaining to the least expensive state changes into the lower-level bits of the hash. For example, changing projection matrices is much cheaper than, say, enabling or disabling lighting wholesale; thus, the bit indicating whether a perspective or orthogonal projection is required would be placed somewhere in the least significant bits of the key, whereas the lighting-required bits would probably be placed somewhere in the middle of the key.
To render, all the the keys are sorted by value and traversed in the resulting order, from lowest value to largest value. Before calling the payload back, the rendering pipeline is setup as required by the information in the key. In a "normally-populated" scene, this means that all objects which require similar rendering states will be batched together. For example, all solid objects which require lighting, texturing, and fog will be rendered contiguously, and all objects requiring transparency, no depth test and an orthographic projection will also be rendered contiguously.
This has the benefit of minimizing the number rendering pipeline state changes, and also prioritizing them so that the most expensive ones are executed the least often. By comparing previous and next rendering keys, it also trivially allows the system to perform the absolute smallest amount of state change required by XORing the two keys to see which bits in the state have changed. This also implicitly does away with any "recall last state set by program and only set it if the value has changed" type of logic.
This arrangement also allows for a nice bit of decoupling, because the payload (be it procedural, like a HUD, or data-driven, like a player model) does not need to know "where" to insert inself into the traditional rendering buckets; it merely has to request the correct state when creating its render key. The payload code is made more elegant, because does not need to deal with any state setup; it only has to ask for the correct state when building its render key, and it can be assured the rendering pipeline will be setup correctly when the renderer calls back. As a bonus, all "stale state" problems (i.e. "I changed my object to render in a different part of the code/rendering pass/whatever, but now it doesn't render properly!") are also solved because each render key contains full information about the required state.
Modelling Aids
As a modelling package, I used Milkshape. My first two tools were created to help in modelling, because as great as Milkshape was, it was missing a few key features.To work on the car I wished to model, I required geometry mirroring, something Milkshape did not handle at the time. To remedy this, I wrote a stand-alone tool called msmirror which looked for specific tags in group names and mirrored geometry right in the .MS3D file. This tool operated on the command-line, and simply transformed the source file by adding or re-mirroring existing geometry. This way, I was able to mirror one side of the car to obtain the other.
I also required more sophisticated UV mapping and texture paging functionality than was available. I thus created a second tool to process .MS3Ds, called msmapper. This interactive tool allowed me to map and texture page each group within the model individually, changing projection types, etc., and save the results back to the model. This granted me much finer control over UVs and texture pages than was otherwise available.
With great pain, I modelled a Subary Impreza WRX STi by pushing vertices, which was great fun and a good learning experience. The resulting polygon mesh is gross, but hey you have to start somewhere.



I still had no good texture for the wheels, however, when one day I saw a beautiful STi parked outside a restaurant right beside where I lived. I walked right into the restaurant and went from table to table until I found the owner, from whom I requested permission to photograph the car and its wheels.

Triangle-Batching Tool
Next, I wrote a tool to perform fanning and stripping on my modelled geometry, since on my GeForce 256 those were the fastest primitive types to use. They cut down both on bandwidth and transformation costs. (Nowadays different bandwidth limitations and large post-transform vertex caches frequently make it more interesting to use triangle lists instead, but that wasn't the case here.)My tool used a a few simple heuristics to do its job. It would begin by first splitting any vertices as required to handle any texturing and normal requirements, since fixed-pipeline OpenGL doesn't support independent indexing for separate attributes. Next, it would create fans around any vertex used by 8 or more triangles:

Lastly, it would create strips by brute force, using a few heuristics. It would first examine each of the remaining unbatched triangles and locate the triangles with the lowest number of unbatched neighbours (treating any triangle pair with an edge in common as neighbours):

In the set of triangles with the lowest number of neighbours, it would iterate over each triangle's vertices and sum the number of triangles who used that vertex. It would the prefer triangles for which the sum was lowest:

The goal of this last heuristic was to make the algorithm try to strip "dangling triangles" on the edge of the mesh sooner, because these were more likely to become orphans later down. Without it, the algorithm frequently picked triangles in the "middle" of the mesh as starting points, which not only left a bunch of orphans on the edges but also sometimes "cut" an arbitrary stripped path from the center of the mesh to its edge, cleaving the space of available triangles for strips to be formed afterwards. I'm definitely not sure this last heuristic is advantageous in the general case, however - it may just be because of my input data. I would have needed to try my tool on more data sets to be sure.
Once the set of starting "problem triangles" was known, a simple brute-force search across all edges of the triangles in the starting set was made to find which edge and winding order yielded the longest strip. This strip was saved and the process was repeated until all triangles were batched.
The quality of the resulting strips and fans depended on the inputs:
 |
| Generally pretty crappy stripping, due to wonky input geometry. Note how the door and windows are a little better since I had an easier time modelling them, and as such the edge topology was much more intelligible. |
 |
| Great fan and strips for the wheel geometry. |
Run-Time Library
Afterwards, the idea was to get this geometry rendering as fast as possible. I wanted a few simple effects: transparency for the glass and a volumetric lighting effect for the headlights. (This last effect simply leveraged destination alpha with a special blend mode to lighten the frame buffer only where the dust particles appeared.)
I also included a real-time blurring test, done by rendering many lightly-transparent quads with the same texture, slightly offset from each other:

My goal with this project was to try out a simple method of minimizing graphics pipeline state changes while rendering a scene, since state changes were (and still are) quite expensive. In order to concentrate on this, I stuck to the OpenGL fixed pipeline model; the scene didn't really require anything programmable anyway, and that axis of exploration was sort of orthogonal to the state change issue.
The idea implemented by photon is simply that each logical object that requires rendering - be it a solid 3D model, a transparent 2D HUD element, whatever - registers a so-called "render key" with the rendering system. As far as the rendering system is concerned, this key is a kind of proxy for the rendered object; when rendering, all render keys in the system are traversed in a specific order outlined below, and they are all told in turn to render their payload. In this fashion the entire scene is rendered.
What's more interesting is what each render key contains, and how the rendering order is determined. When generated, a render key is made to contain a 32-bit "hash" of the rendering state required for the payload to be delivered. (More bits could be used for a more complex set of states.) For example, it might indicate that it requires a perspective projection, with client states enabled, texturing enabled, no texture coordinate generation, normal normalization on, lighting off, fog off, depth testing enabled, no culling, standard blending, all in the 2nd global rendering pass with a given texture ID, etc. This information is combined into the 32-bit key in such a way as to encode information relating to more expensive state changes in the high-level bits of the hash, and information pertaining to the least expensive state changes into the lower-level bits of the hash. For example, changing projection matrices is much cheaper than, say, enabling or disabling lighting wholesale; thus, the bit indicating whether a perspective or orthogonal projection is required would be placed somewhere in the least significant bits of the key, whereas the lighting-required bits would probably be placed somewhere in the middle of the key.
To render, all the the keys are sorted by value and traversed in the resulting order, from lowest value to largest value. Before calling the payload back, the rendering pipeline is setup as required by the information in the key. In a "normally-populated" scene, this means that all objects which require similar rendering states will be batched together. For example, all solid objects which require lighting, texturing, and fog will be rendered contiguously, and all objects requiring transparency, no depth test and an orthographic projection will also be rendered contiguously.
This has the benefit of minimizing the number rendering pipeline state changes, and also prioritizing them so that the most expensive ones are executed the least often. By comparing previous and next rendering keys, it also trivially allows the system to perform the absolute smallest amount of state change required by XORing the two keys to see which bits in the state have changed. This also implicitly does away with any "recall last state set by program and only set it if the value has changed" type of logic.
This arrangement also allows for a nice bit of decoupling, because the payload (be it procedural, like a HUD, or data-driven, like a player model) does not need to know "where" to insert inself into the traditional rendering buckets; it merely has to request the correct state when creating its render key. The payload code is made more elegant, because does not need to deal with any state setup; it only has to ask for the correct state when building its render key, and it can be assured the rendering pipeline will be setup correctly when the renderer calls back. As a bonus, all "stale state" problems (i.e. "I changed my object to render in a different part of the code/rendering pass/whatever, but now it doesn't render properly!") are also solved because each render key contains full information about the required state.
No comments:
Post a Comment